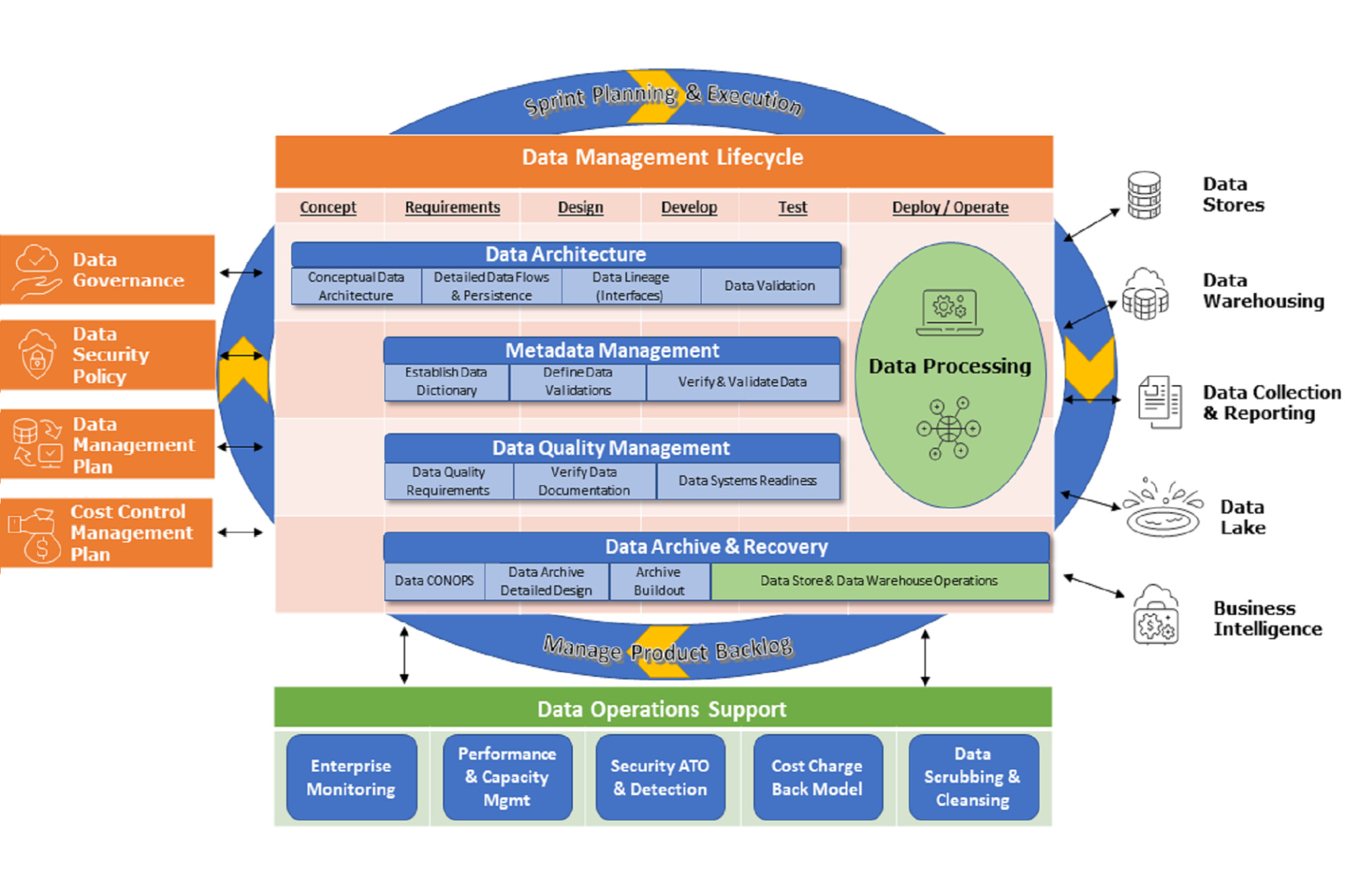
IBR’s Data Management Center of Excellence (CoE) as depicted in the graphic above starts with The Foundation (left) of defined management plans and mature enterprise policies using ITIL and PMBOK best practices. These plans and policies feed into the Data Management Lifecycle (middle) using agile methodology to build and manage various Data Functions (right). Your data needs constant care and feeding through a strong Data Operations Support (bottom) mechanisms to maintain data usability and integrity.
Below is more details of The Foundation building blocks:
- Data Governance – a set of principles and practices by the various enterprise stakeholders that ensure high quality through the complete lifecycle of your data.
- Data Security Policy – a set of standards and technologies that protect data from intentional or accidental destruction, modification or disclosure ability.
- Data Management Plan – a series of documents that describe the type of data collected or generated by the enterprise, how the data will be organized, the protection of the data, the access and sharing of data, and preservation of the data.
- Cost Control Management Plan – a plan to establish a support baseline service for all system and data processing services along with a tiered support structure to define the addition services required for mission critical functions and various levels in between.
Without a proper foundation, many well-constructed data lakes and data warehouses can become "data swamps" of disorganized pools of data that are difficult to use, understand, maintain, and share across the enterprise. The greater the quantity and variety of data, the more significant this problem becomes and uncontrollable to manage.
IBR has learned through our in-depth 2010 and 2020 Decennial experiences that many problems can be avoided through timely effective management methods. For example, problems may include undetected duplications across and within data stores, incorrect sourcing/usage conflicts (data should for specific purpose), and misinterpretations of various versions of data. These problems obstruct the correct understanding of the stored information due to insufficient consistency and standardization, unshared data across enterprise components (due to privacy/security constraints), misinterpretations of source data contexts, and unspecified future usage of the data.
Data persistence is also an under-controlled aspect of data, in which data may partially flow through the enterprise to "pockets" of storage within the enterprise, but do not reach the expected final destination in a timely manner. In all of these issues, the "life-cycle" of the data must be defined, collaborations/sharing and timeframes identified, and records management requirements considered. Enterprise data architecture addresses these risks, and Data Management is designed to prevent and mitigate these problems by establishing basic foundational governance principles, practices, standards and documentation.
Once these foundation building blocks are in place the data core components can be implemented with a focus on the following:
- Data Architecture – the process of specifying requirements and designing the structure, transfers, storage and usage of data at all levels of the enterprise.
- Metadata Management – the processes and tools used to document the information describing various facets of an asset, improving its usability, consistency, and integrity across the enterprise.
- Data Quality Management – the ongoing policies and processes that ensure and maintain the Consistency, Accuracy, Completeness, Auditability, Orderliness, Uniqueness, Timeliness of the enterprise data assets – these include the development and maintenance of life-cycle phase checklists, participation in gateway reviews, data lineage interface validations, and system testing oversight.
- Data Archive & Recovery – design and implementation methods and considerations necessary to retain consistent performance and to provide the ability to "rewind" data to a prior state in manageable pieces for operational nimbleness and data integrity.
As you can see, Data Management is a series of complex and involved processes with several feedback mechanisms. When it comes to implementation of a Data Management ecosystem, IBR’s Data Management CoE follows these simple principles in helping clients to make the most of their data.
- 1. Dip your toe. Don't dive straight in.
At IBR, we believe in an agile approach in everything we do. It can be tempting for companies to pull all sorts of data sources into a data lake and start experimenting thinking that is a valid agile approach. Instead, it's best to start small, with a couple of clearly defined projects that can tackle a known problem. Find something that can offer a quick win and you can enjoy a good return on investment and gain valuable knowledge of what you need to make your data work effectively before rolling out large-scale plans. - 2. Focus on data quality and shared Metadata.
Might need to do a little spring cleaning first. One of the biggest barriers to success in data management is data that is poor quality, inaccurate or outdated. Cleaning up data before it is used in any analytics processes is therefore essential. In addition, periodic cleaning must be an on-going effort to identify and delete duplicate data, spot data that's no longer relevant, and inconsistencies against defined Metadata standards. - 3. Keep access simple but security strong.
Developing effective access controls is always a tricky balance between convenience and security, but it is well worth taking the time to ensure that each individual has the level of access that's appropriate for their role, rather than implementing blanket policies which are either too restrictive for some people or may allow others to access data they should not be able to view. It is a delicate balance in allowing easy flow of data but being mindful about privacy concerns and government regulations such as the EU's General Data Protection Regulation. - 4. Don’t forget about operations.
It is easy and fun to focus on the technical aspects in building a data management program. Often it is the operational details that come to haunt enterprise data efforts, leading to a slow erosion of performance, an undetected data breach, and the inability to filter out the “noise” to extract meaningful data results. It is critical to focus on building in systematic and repeatable processes in order to establish enterprise monitoring, to manage security control, to recover data at known points in time, and to archive data while maintaining performance. - 5. Not everyone is equal.
Not everyone gets a participation trophy when it comes to the reality of managing cost across the enterprise. A Service Level Management “one size fits all” model does not provide an enterprise the flexibility to manage cost effectively. IBR’s experience has shown that a Tiered Support structure (i.e. Platinum, Gold, Silver service levels) gives the Enterprise the flexibility to ensure mission critical systems have the best service but also allows that all systems have adequate support without breaking the bank. Cost transparency is achieved through a cost charge back model as defined in the cost control management plan
SUPPLEMENTAL INFORMATION OF KEY CONCEPTS
Data Architecture should begin during the first phase of any implementation. It includes the specification of data record structures, use cases for data flows, anticipated data lineage, and planned data persistence in line with the enterprise/system architecture design. Data Architecture provides continuing oversight to all data management processes.
Metadata is any information that describes and clarifies the data that was generated/collected (e.g. date/time of a user response, employee payroll identification information, etc.) and paradata describes how it was collected (e.g. the method used, number of keystrokes, whether it was updated and how often, etc.). In a sense, all data is metadata – it always provides the context or clarifies an object or another set of data. A person's name, age, number of children, and birthdate describes/clarifies the person. Therefore, each component of a data record must be described, standardized and managed. A metadata registry as an enterprise-level data dictionary is always recommended, with data structures and components standardized throughout the organization.
Data lineage includes the data origin, what happens to it and where it moves over time. Data lineage gives visibility while greatly simplifying the ability to trace errors back to the root cause in a data analytics process. Data lineage can help with efforts to analyze how information is used and to track key bits of information that serve a particular purpose.